Most inference posts pick a shiny optimization, run it against a vague benchmark, and report a percentage. I want to go the other way.
Last weekend, while talking with Tanay from Sarvam AI, I first came across this phrase: "token factory". Now, sitting in a lab full of idle GPUs, I got this idea to simulate different workload profiles for different "token factories".
Not every optimization helps every workload. For a company which deals only with RAG and summarisation, I would not bother with speculative decoding. Similarly for something like Character AI, with short conversations as the main goal, I would focus heavily on optimizing the decode stage.
I couldn't find any case-by-case study on this exact topic, so I tried to do it myself.
The setup
A single RTX 6000 Ada for now, running vLLM. We will be serving Qwen2.5-14B-Instruct with an 8k context window and at 90% GPU memory utilization. I created a small harness using Claude Code to make it easier to iterate between configurations, launch experiments, and collect metrics, along with a workload generator that produces four request classes: SISO (short input, short output), SILO (short input, long output), LISO (long input, short output), and LILO (long input, long output).
For the baseline, I wanted something resembling a busy Monday morning. Requests arrive according to a Poisson process at 32 requests/sec, with up to 128 concurrent requests in flight. The workload is intentionally mixed - hundreds of short chat style requests, long form summarization jobs, code generation heavy prompts, and long context generation tasks all competing for the same GPU. Now we can observe which bottlenecks emerge naturally under realistic pressure.
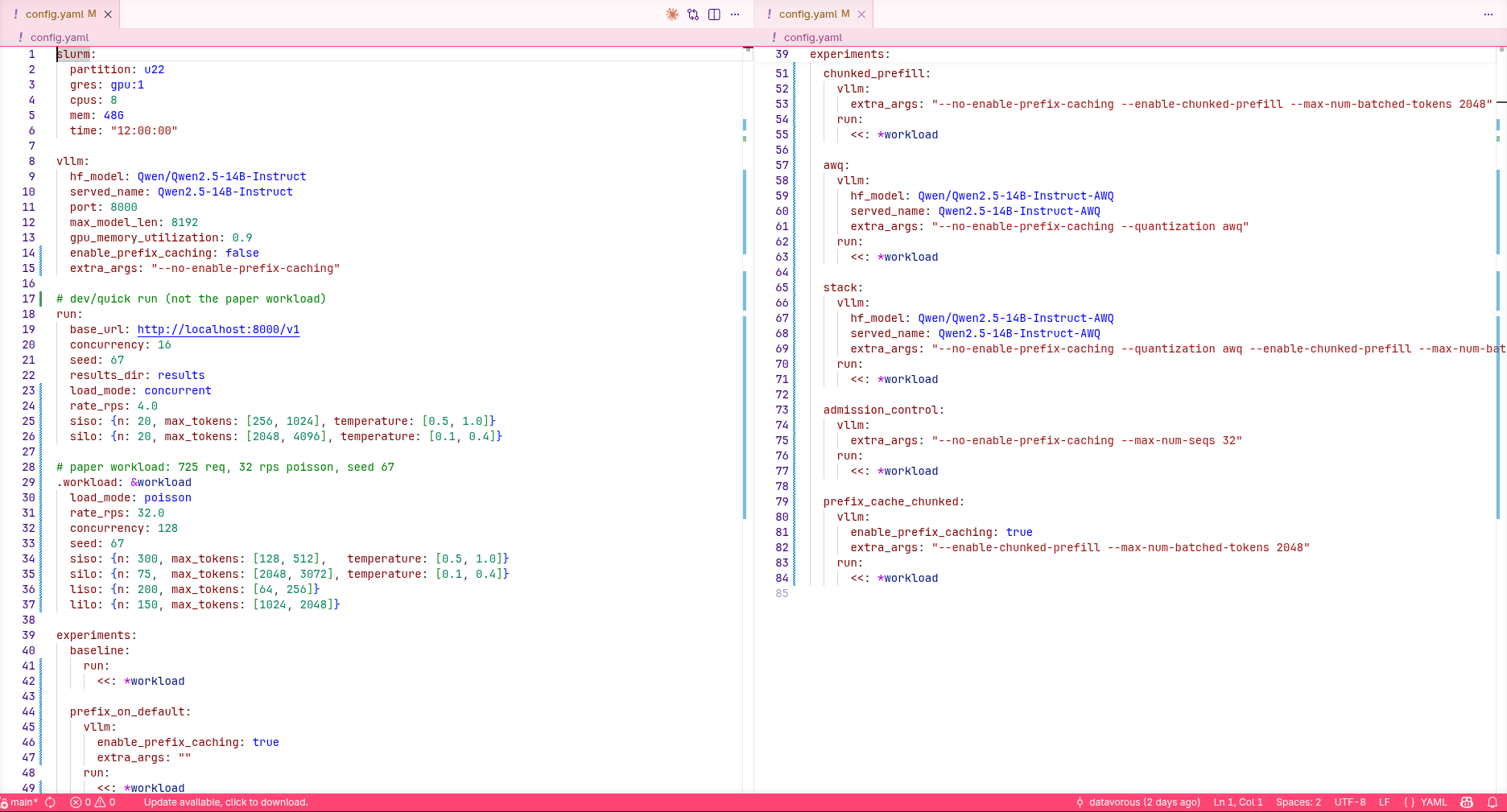
I use a config.yaml file to carry out my experiments. The default run: block is overridden under the experiments: block. In this case, the baseline is just the defaults plus a few key overrides (Poisson at 32 RPS, 128 concurrent). Sweep mode exists in the harness but the baseline doesn't touch it.
This whole setup is a proxy. Real production traffic is unavailable and would be unrepeatable anyway. The shape of the curves and the relative effect of each optimization will transfer to a similarly configured production environment, it'd be just the deltas.
The eyes they never lie, except when they do.
The first thing I did after the baseline run was build the heatmap of prompt tokens against completion tokens, expecting four neat clusters at the four corners of the workload.
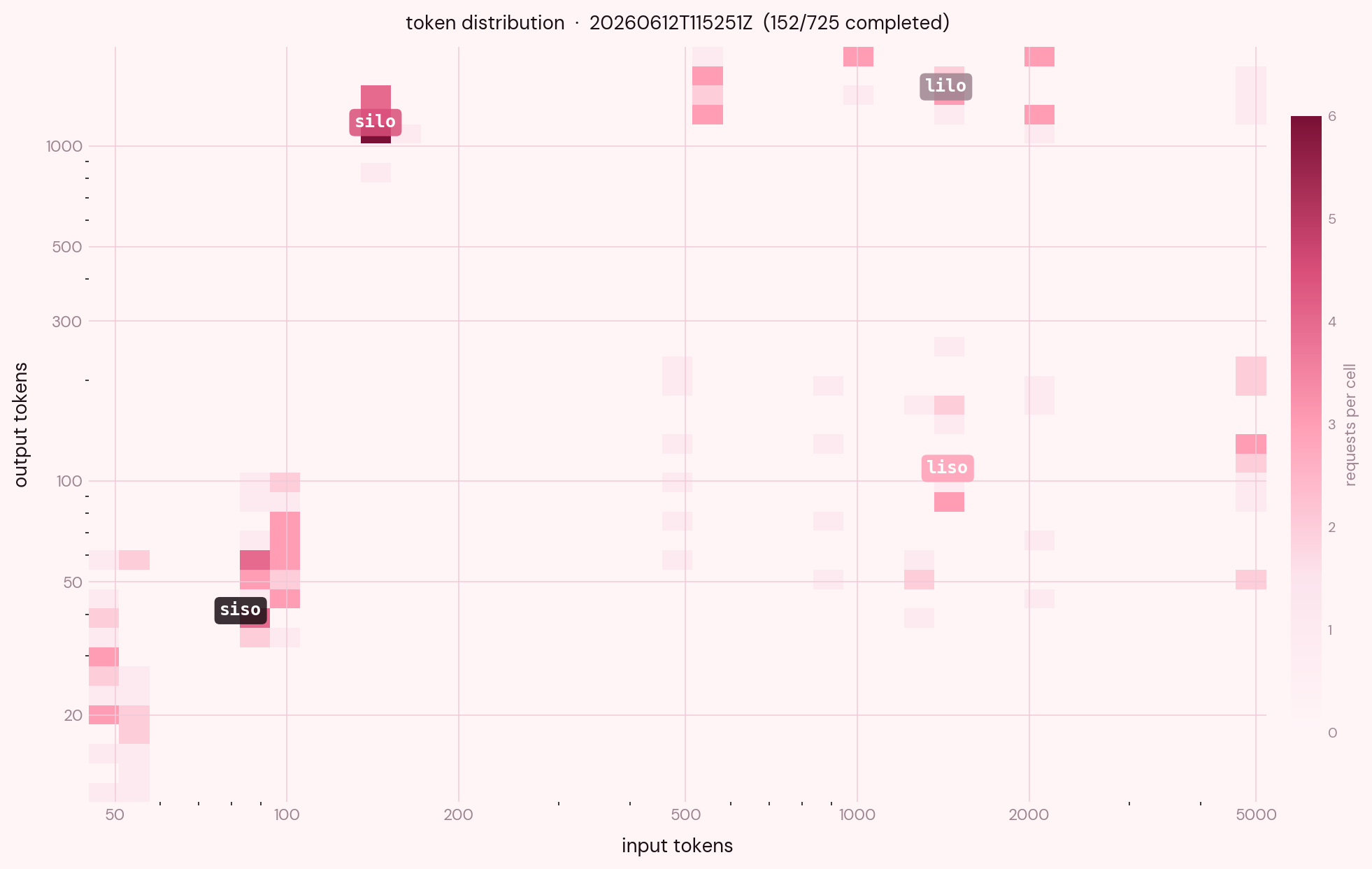
Look at the title. The heatmap draws roughly a fifth of the requests the run actually sent. The other four-fifths are not in the picture because the y axis is completion tokens and a request that never completed has no value to place there. So they vanish from the figure entirely. Looking at where the density lives, the only region that read as a real distribution is the SISO cluster at the bottom-left, while the others are pretty scattered.
Now this is lowkey survivorship bias. I wanted to see how many survived and how many did not, so I plotted completed and failed requests together against input token length.
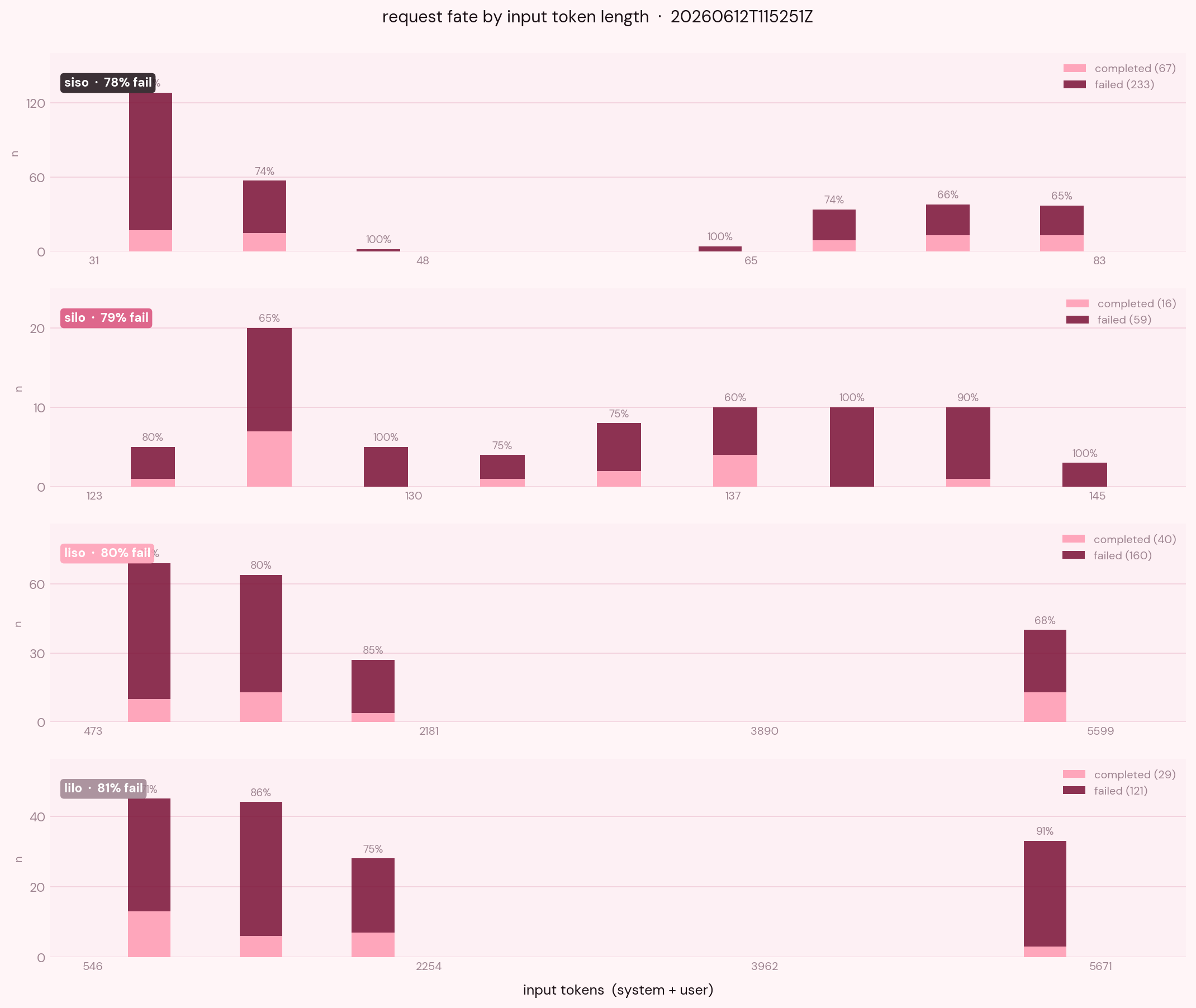
Roughly four out of every five requests offered to this server did not come back. And the failure percentage points all hover around 78 to 81%. Uniformity...what can that mean?
One hypothesis is that, if the server were doing anything intelligent under pressure (say fair share scheduling, biased toward cheap requests) i.e. anything intelligent under pressure which could have prioritized one shape over another then things could have looked different.
Things are flat because the scheduler, when it runs out of room, is not choosing. Requests arrive faster than the server can finish them, so they pile up in vLLM's waiting queue. The scheduler tried to admit as many as fit in KV memory, the KV fills, the scheduler has to preempt already-running sequences to make room for new ones, the preempted sequences go back to the queue to be recomputed later, and the loop continues until the client times out. As nothing is being chosen against, the damage falls on everything.
The vLLM scheduler does ship a priority based policy that would preempt the lowest priority running request instead of just popping whatever sits at the back of the queue, but it requires clients to pass a non standard priority field on every request, and no off the shelf OpenAI compatible client does that. What you get is the FCFS behaviour I just described.
What this gives us, at the close of the diagnostic stage, is a sense of where each of the four traffic shapes will need attention.
SISO loses most of its requests despite each one being trivially small to serve, which means the bottleneck for short traffic is the queue. SILO loses most of its requests with the longest output bins dying most, which means the bottleneck there is decode throughput per stream. LISO loses most of its requests with the longest input bins dying most, which means the bottleneck is prefill cost. LILO loses most of its requests for both reasons at once.
These are the four hypotheses which I will be testing, but before that we need to define what counts as "good". We need to know what this hardware should be capable of because an honest optimization story needs to know how close we are to them.
What counts as good
Throughput is the number which every inference benchmark reports, and (if I understand correctly) is the easiest to lie with. Instead, the honest metric is goodput. BentoML explains it aptly:

The SLOs for the rest of this post I will keep deliberately generous such that our otherwise good optimizations are not accidentally invalidated.
SISO: TTFT <5s. SILO: ITL P95 <250ms. LISO: TTFT <5s. LILO: ITL P95 <250ms.
The disaster baseline's goodput against these SLOs is close to 0. Moreover, I came across Gil Tene's presentation on coordinated omission (slides here) during my research and I think they are worth mentioning here.
In simple words, under overload, even the load generator can fall behind schedule. Measuring latency from when a request actually left the client hides the time the user was already waiting, so we measure from when the request was supposed to be sent.
Similarly, the beginning and end of a load test contain startup and shutdown effects that do not reflect normal operation. We therefore compute percentiles only over the stable middle portion of the run.
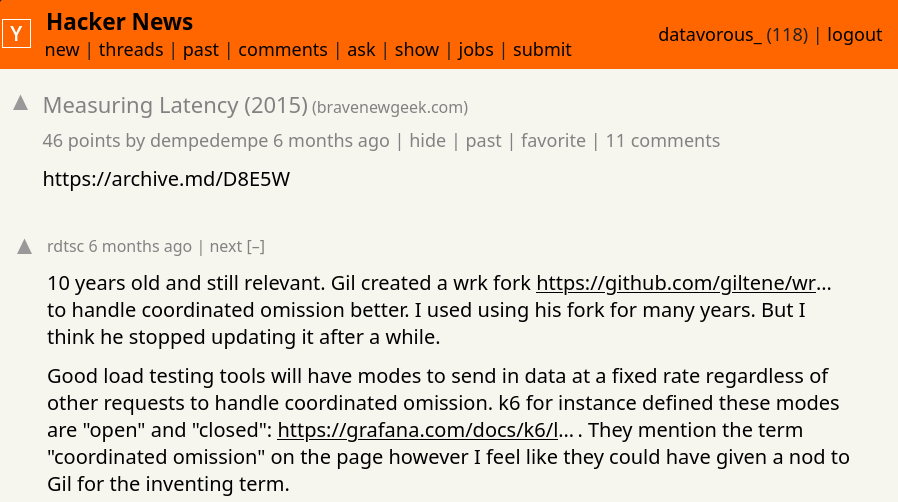
A later audit found two bugs: latency is measured from actual send time, not the intended Poisson arrival time, and per profile %iles skip the stable window trim. Both make the absolute numbers in this post optimistic. The relative ordering of optimizations is unaffected. Fix is in the followup.
What this hardware should actually do
All references were taken from Nvidia's Ada architecture whitepaper (pages 28-30 are relevant).
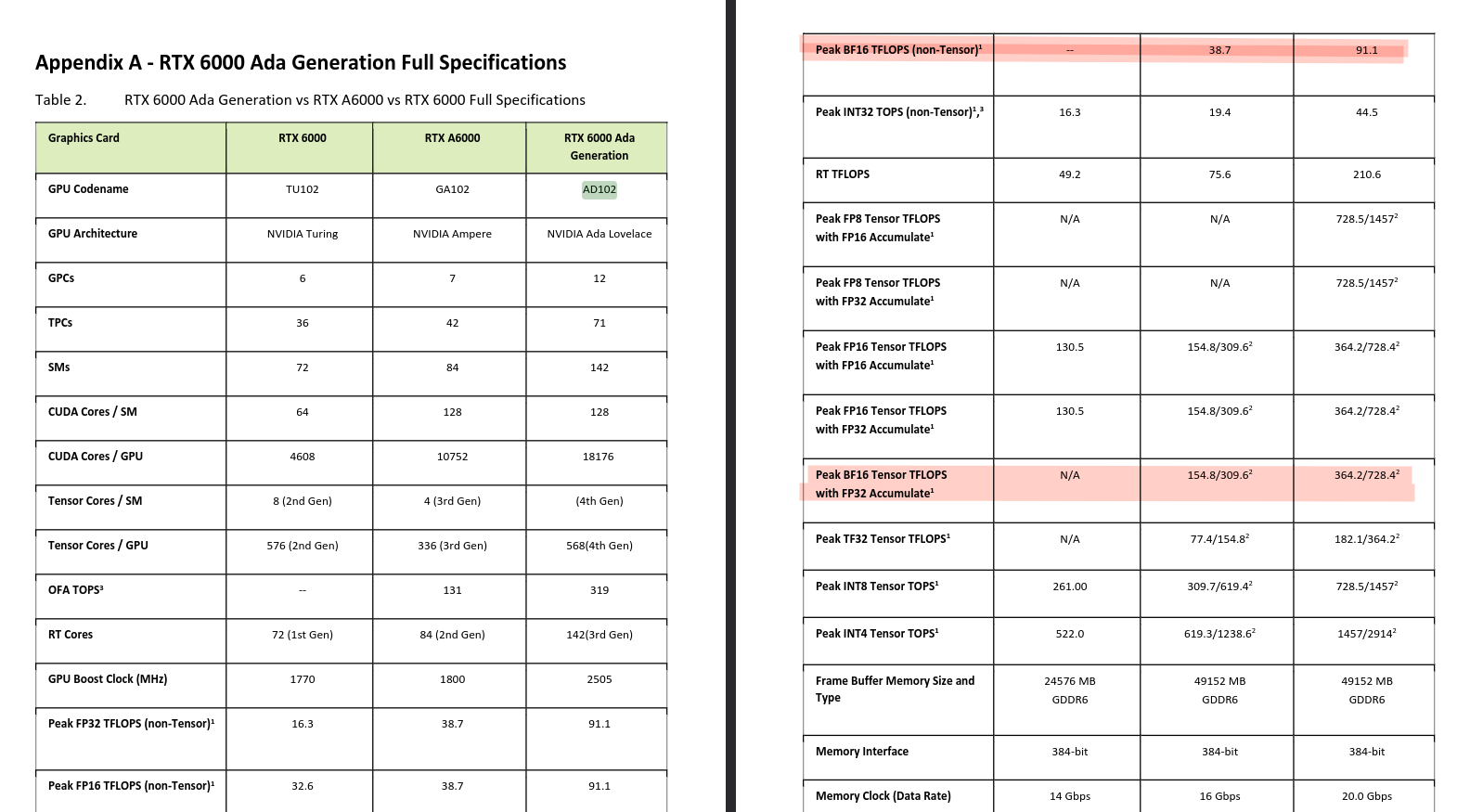
We get a BF16 dense tensor compute of 364.2 TFLOPS, memory bandwidth of 960 GB/s, and 48GB of VRAM.
There is the prefill phase, and there's the decode one. Prefill is compute bound, and most of the computations are in the form of GEMMs. With our model (Qwen2.5-14B), we would need roughly 28 GFLOPs per prompt token (2 * params * tokens). That gives us the theoretical prefill ceiling of around 13k toks/s before overhead.
Decode is memory bound. It's just a matrix-vector op (GEMV) with nearly zero arithmetic intensity. The bottleneck is entirely consumed by streaming ~28 GB of weights across the bus for every single token. Dividing 960 GB/s by 28 GB caps a single stream at ~34 tokens/sec (Nvidia Ada whitepaper), which is the upper bound before KV reads, attention compute, and kernel launch overhead are accounted for. The only way to save throughput here is batching.
Coming back to KV cache, every active sequence holds a key value tensor of roughly 196kb per token. After vLLM loads ~28 GB of BF16 weights and reserves overhead, ~15-17GB of the 48GB is left. That's around 80k to 90k KV tokens in flight.
Now an average LILO holds around 3,000 KV tokens at steady state, meaning just 25 concurrent requests would completely use up our ~80k token budget. This is why our physical memory caps our effective concurrency at ~28 before pinning KV at 100%. That's why the baseline collapsed! The card simply lacks the memory depth to hold this many long context requests at once. vLLM's actual KV budget after framework overhead lands closer to 57k tokens, which is what shows up in the experiments below.
Predictions before measuring
Some of them failed after I ran the experiments on real hardware.
- If we use prefix caching then the cache would be storing KV blocks for token sequences it has seen and would reuse them on subsequent requests that start the same way, skipping the prefill GEMM for the shared portions. LILO and LISO should have their TTFT drop substantially (as long prompts overlap due to their code file corpus), and SISO and SILO would barely move.
- Chunked prefill in here would break prefills into pieces and interleave them with decode steps. A large token prefill on the baseline would be monopolizing the GPU for over a second, starving every other request's decode. I am predicting that LISO/LILO TTFT would improve dramatically, SISO would improve indirectly, and SILO would get slightly worse.
- Quantization (AWQ to 4bit) would roughly quarter weight memory and should double decode throughput, as each step will read a fraction of the bytes from the HBM. SILO and LILO are direct beneficiaries. Similarly SISO would benefit indirectly. LISO would benefit least for being prefill bound.
- Stacking multiple methods (chunked prefill + AWQ) i.e. stacking two known good levers to see if they compose well. Perhaps the best for LILO.
I have intentionally scoped down my experiments to these 4 cases, otherwise the post will be longer than my will to live.
Prefix caching
I turned on automatic prefix caching, left every other variable identical to the baseline, and reran. Overall, the completion rate rose from 21% to 75%, and throughput increased 4.6x.
| Metric | Baseline | Cache on |
|---|---|---|
| Completion rate | 21% | 75% |
| Throughput | 144 tok/s | 661 tok/s |
| P50 | 40.9 s | 4.5 s |
| Cache hit rate | - | 71.60% |
Throughput increased 4.6x - I would like to be very careful with this claim. Prefix caching skips prefill work for tokens it has seen before. More requests fit through, so aggregate output goes up. No individual stream is generating tokens faster. The 4.6x is the system breathing again, not a decode speedup (benchmark,
design doc).
What the cache is actually catching is the file bodies in the LISO and LILO corpus, being reused across requests after the model sees each file once. With five source files in the corpus and a few hundred requests drawing from them, every file ends up cached after a few sightings, and the rest of the requests effectively skip the expensive prefill entirely - which is exactly the workload that prefix caching is designed for: document QA, code review, RAG style workloads where the same content reoccurs across many user queries.
| Metric | Baseline (s) | Cache on (s) | Speedup |
|---|---|---|---|
| SISO | 56.6 | 4.67 | 12x |
| SILO | 35.5 | 4.56 | 7.8x |
| LISO | 22 | 4.4 | 5x |
| LILO | 38.1 | 3.92 | 9.7x |
The surprise was in the profile breakdown though. I predicted that LISO and LILO would benefit most, since they were the profiles with the long shared prefixes, and they did benefit, but SISO benefited more.
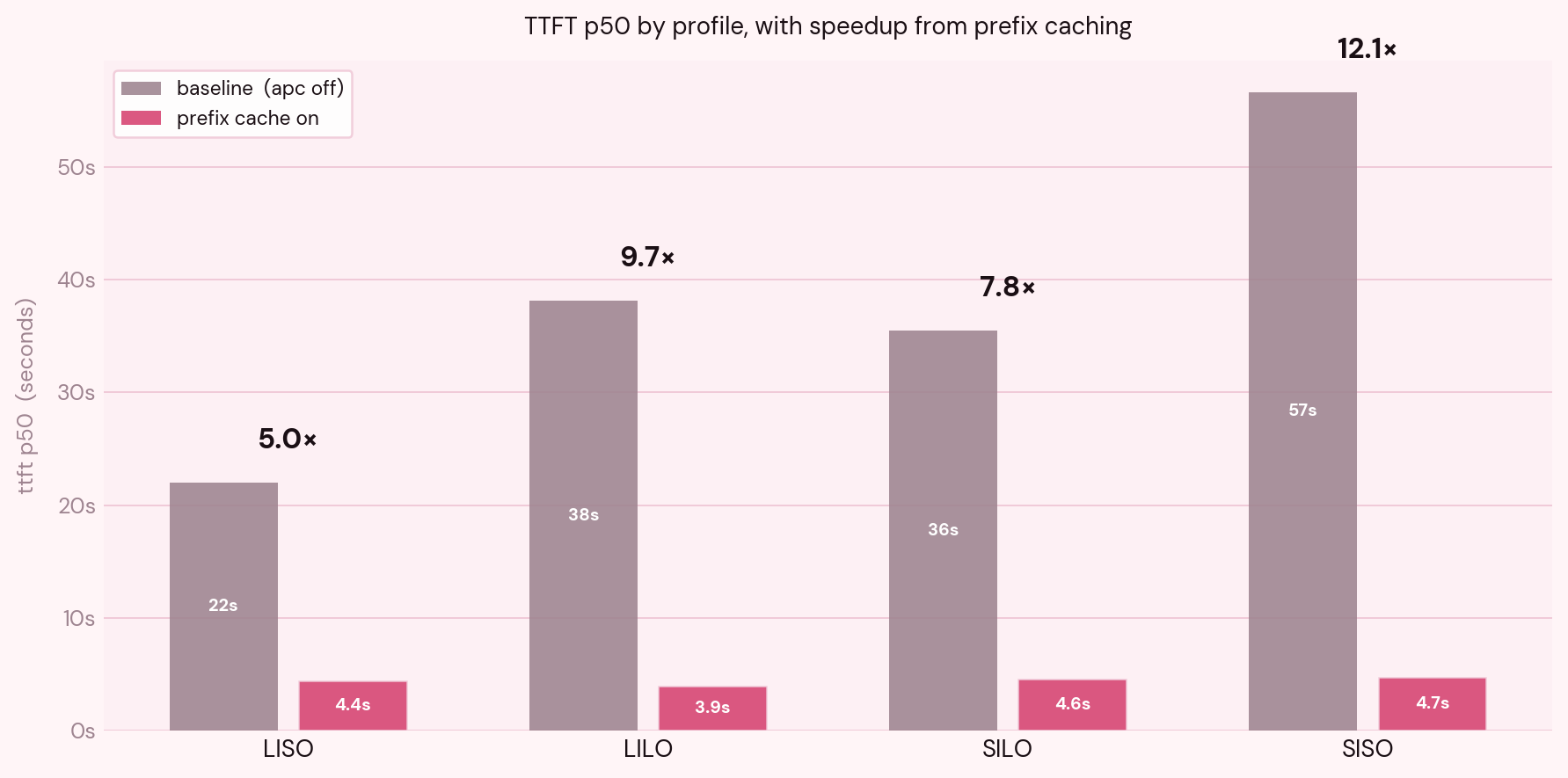
Which made no sense if you assume the cache is only helping the profiles whose prompts it can actually reuse. It took me a minute to see the most plausible (causal?) explanation. The timing is consistent with SISO sitting in vLLM's waiting queue behind LISO and LILO requests whose long prefills were monopolizing the GPU: in the baseline, SISO's TTFT P50 is 56.6s despite a median prompt of 83 tokens, while LISO's TTFT P50 is 21.9s with a median prompt of 1440 tokens. From there we can see that a 17x shorter request waiting 2.6x longer for first token is hard to explain without queue contention. Turning on the cache made LISO and LILO prefills largely disappear (73.7% cache hit rate), and SISO TTFT dropped to 4.67s. The bottleneck for the cheap profiles was most likely the expensive profiles' prefill cost. The per profile queue time (vLLM's vllm:request_queue_time_seconds split by request tag) would confirm this directly.
Chunked prefill
As we saw earlier, a long prefill monopolizes the GPU until it's done, during which every other request's decode is frozen. Chunked prefill breaks the prefill into pieces (in this case I tried it with 2048 tokens at a time) and interleaves them with decode steps for in flight requests. That makes a 4000 token prefill become two chunks with decode work happening in between.
I expected this to improve LISO/LILO TTFT (their prefills no longer block others), improve SISO indirectly (it stops queuing behind those prefills), and mildly hurt SILO ITL (its decode now shares the GPU with prefill chunks of other requests).
| Metric | Baseline | Chunked prefill |
|---|---|---|
| Completion rate | 21% | 32% |
| Throughput | 144 | 251 |
| TTFT P50 | 40.9 s | 188 s |
| ITL P50 (SISO) | 182 ms | 101 ms |
| ITL P50 (LILO) | 216 ms | 111 ms |
| Preemptions | 262 | 412 |
The metric I predicted it would show up in was wrong, though the mechanism I predicted was partially right.
Chunked prefill spreads each prefill across multiple scheduler iterations, which keeps decode progressing instead of freezing it. But it also means any individual request's prefill takes longer wall clock time to complete, because it's now competing with decode for slots. TTFT got worse because the cost of slicing appears to have exceeded the benefit of unblocking at this arrival rate. Chunked prefill is designed to let new requests start sooner instead of waiting behind a monolithic prefill, but at sustained overload, every request pays the slicing tax and only some of them benefit from the unblocking. ITL improved because no single prefill can monopolize the GPU anymore, so decode steps come out more regularly.
The throughput number counts both prefill and decode tokens. Chunked prefill spreads prefill work across more iterations, so per-iteration token counts go up while per-request wall-clock latency goes up too. The aggregate metric and the per-user metric are measuring different things.
If I only looked at TTFT, I would probably call this a regression. If I only looked at aggregate throughput, I would probably call it an improvement. Preemptions also rose from 262 to 412 because chunked prefill keeps more prefills concurrently in flight instead of serializing them, which raises sustained KV pressure and triggers more preemptions.
KV usage still sits at 100%. Chunked prefill, like caching before it, is now changing how the scheduler spends that budget.
Quantization, with a surprise
Decode is memory-bandwidth-bound, so if weights go from BF16 to 4 bit (Qwen2.5-14B-Instruct-AWQ), each decode step should have to pull roughly a quarter of the bytes from HBM. You don't quite get a 4x speedup because dequantization still exists, but nearly 2x improvement in single stream decode didn't seem unreasonable. The other thing I expected was that the smaller weights would leave a lot more VRAM available for KV. On this setup, that should have been almost comically helpful because the workload is visibly KV bound. In practice, the in flight KV budget jumps from around 57k tokens to 171k tokens.
The freed VRAM did get handed back to the KV pool, the budget really did triple, and preemptions dropped from 262 to 132 because the scheduler could now afford to keep more sequences resident instead of constantly evicting and re-admitting them.
| Baseline (BF16) | AWQ (INT4) | |
|---|---|---|
| Completion rate | 21% | 34% |
| Throughput | 144 tok/s | 189 tok/s |
| TTFT P50 | 40.9 s | 57.6 s |
| ITL P50 (SISO) | 182 ms | 557 ms |
| ITL P50 (LILO) | 216 ms | 316 ms |
| Preemptions | 262 | 132 |
| KV budget | 57k tok | 171k tok |
But the decode got slower. SISO ITL is roughly 3x worse and LILO degraded by almost 50%.
Though LILO degraded less than SISO likely because LILO runs at effectively higher per step batch (more concurrent decode tokens), which is closer to the regime where AWQ kernels amortize dequantization cost.
Throughput did get better, but only from 144 tok/s to 189 tok/s, probably because the larger KV budget was just allowing more requests to coexist. Hence the extra throughput wasn't coming from any individual request with faster decoding.
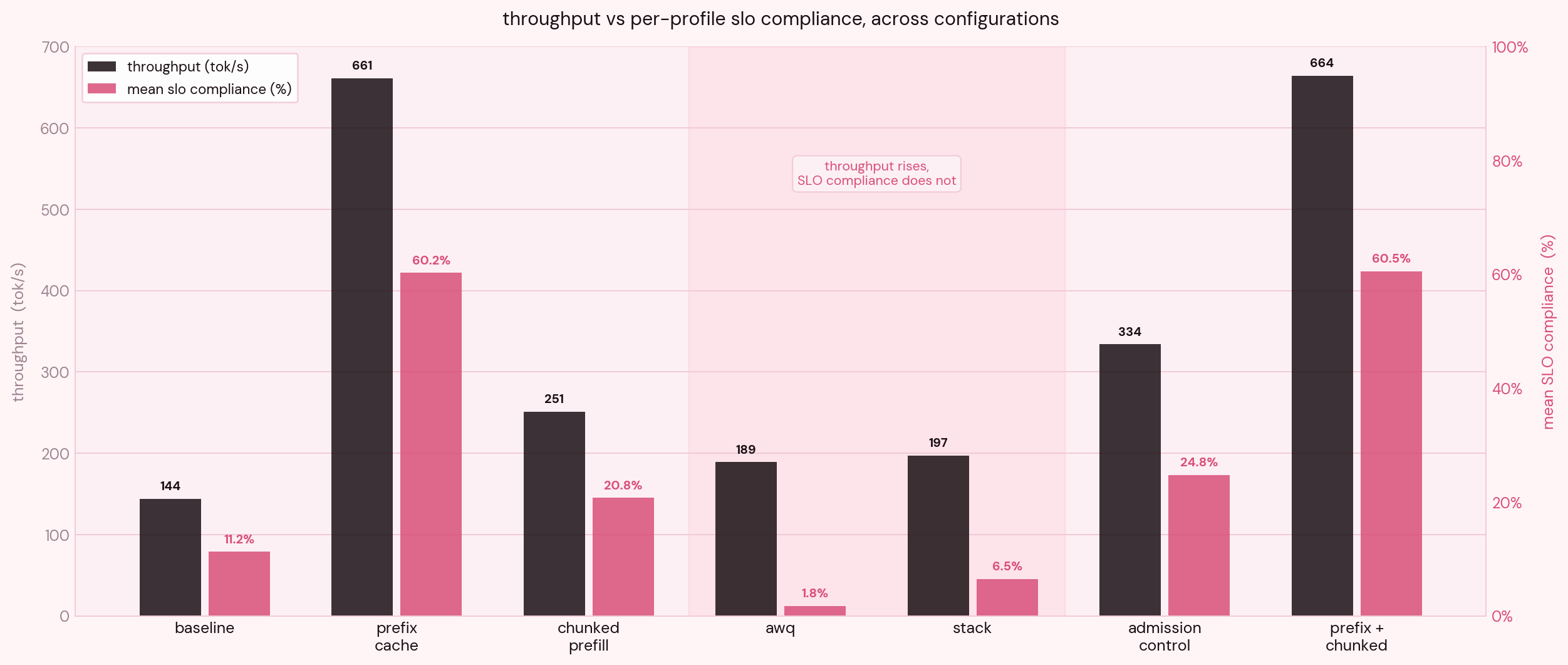
The server is doing more work overall, but each stream is progressing more slowly. From a user's perspective, every token arrives later even though the dashboard says throughput went up.
The regression had to be somewhere higher in the stack, and once I looked at what AWQ kernels actually do, it was obvious. AWQ is a W4A16 storage scheme, where weights are stored as INT4 with FP16 scaling factors, but every matmul dequantizes them back to FP16 and runs the GEMM in FP16 (vLLM source). At high batch sizes the dequantization overhead disappears into the pipeline. At the m=1 GEMV shape that decode uses, the dequantization cost sits on the critical path without being amortized across a batch dimension. (This is a documented behavior btw
PR #2566,
issue #2268) vLLM's AWQ path was designed for prefill-heavy throughput, not interactive decode .
The system level scheduler becomes happier because memory pressure drops, while the individual decode path becomes slower because each token now carries extra work that the hardware shape can't hide. These are the two things happen simultaneously.
AWQ + chunked prefill
The obvious question after the previous two sections was whether these two techniques can fix each other's weaknesses. AWQ's biggest problem was per-token decode latency, especially on SISO where ITL had exploded to 557ms. Chunked prefill's biggest win was making decode more regular by preventing long prefills from monopolizing the GPU.
Intuitively, they seemed complementary. AWQ gives me a much larger KV pool, chunked prefill gives decode more opportunities to run, and maybe the ugly ITL numbers disappear. So I turned both on and reran everything.
The answer? Yes.
And, uh..not really
| Baseline | AWQ | Stack | |
|---|---|---|---|
| Completion rate | 21% | 34% | 36% |
| Throughput | 144 tok/s | 189 tok/s | 197 tok/s |
| E2E P50 | 110 s | 119 s | 91 s |
| ITL P50 (SISO) | 182 ms | 557 ms | 367 ms |
| Preemptions | 262 | 132 | 258 |
Chunked prefill does pull AWQ's ITL back in the right direction. SISO drops from 557ms to 367ms, which is still substantially worse than baseline but no longer catastrophic. E2E latency also falls to 91 seconds, which actually ends up being the best E2E number in this entire post. So if the thing you care about is getting long jobs finished sooner, the stack genuinely works.
The part I didn't expect was what happened to preemptions. AWQ by itself had cut them almost in half because the scheduler suddenly had three times more KV headroom. After enabling chunked prefill, they climbed back to roughly the original disaster baseline level (~260). The KV budget is still at 171k tokens. But chunked prefill admits more concurrent in flight prefills instead of serializing them, which is consistent with what consumed the additional headroom which AWQ prevoiously provided.
So the two optimizations both operate on the same resource from different directions. Stacking them doesn't preserve both benefits.
:(
This also ended up being one of the most deceptive results in the entire experiment. When I looked at per profile SLO compliance, it was among the worst configurations: 1% on SISO, 1% on SILO, 9% on LISO, and 15% on LILO. The stack really is getting more work done. It's just getting more work done by fitting more requests into the same period of time, not by making any individual request feel faster. The server is happier. The users definitely won't be.
The tradeoff matrix
This is my entire post summarised. Two additional configurations appear that weren't covered in their own sections. Admission control caps the number of concurrently running requests (I used vLLM's --max-num-seqs) to keep KV from filling and triggering cascading preemptions, it helped with long output profiles, but does nothing for SISO. Similarly prefix + chunked stacks automatic prefix caching with chunked prefill was pretty much identical to prefix caching alone, at higher preemption cost.
| Baseline | Prefix | Chunked | AWQ | Stack | Admit | Prefix+chunk | |
|---|---|---|---|---|---|---|---|
| SISO (chat) | 0% | 43% | 1% | 0% | 1% | 0% | 44% |
| SILO (code gen) | 20% | 68% | 44% | 0% | 1% | 52% | 68% |
| LISO (review/RAG) | 6% | 56% | 6% | 5% | 9% | 6% | 56% |
| LILO (refactor) | 19% | 74% | 32% | 2% | 15% | 41% | 74% |
SLO compliance: fraction of offered requests that met the per-profile latency budget. SISO/LISO: TTFT <5s. SILO/LILO: ITL P95 <250ms. Bold = above 40%.
Look at the AWQ column. 189 tok/s throughput, sounds fine, but zero SISO compliance, zero SILO compliance, 2% LILO. Nobody is getting a usable response. And that's THE GAP between throughput and goodput.
The prefix caching column is the only one that doesn't look broken. Every profile above 40%, 4/4. Everything else either flatlines on SISO or has at least one profile in crisis. Automatic prefix caching is enabled by default in vLLM v1 (docs), which has been the default engine since 0.8.1. If you're on a recent vLLM, this is already on. If you're on an older version, then turn it on, perhaps?
Two things in the matrix are unintuitive in my opinion.
Admission control helped SILO and LILO (52%, 41%) but did nothing for SISO SLO compliance, it stayed at 0% even though completion rate hit 44%.
Lower in flight concurrency does help the queue drain faster, but at 32 RPS the HTTP queue still grows unboundedly, and SISO's TTFT budget is too tight to survive any meaningful wait.
Prefix caching plus chunked prefill is statistically identical to prefix caching alone. The reason is that prefix caching skipped 73.7% of the prefill work, which means there's almost nothing left for chunked prefill to chunk. It doesn't conflict - it just has nothing to do! And then it charges you 405 preemptions (up from 334) for the privilege of doing nothing.
If you turn on prefix caching, you're mostly fine across all four profiles, given your workload has content overlap. Whereas chunked prefill alone is a worse production config than baseline for any SISO heavy product (1% SLO compliance vs 0% is not a win !!), AWQ is dangerous on interactive workloads because its kernel path dequantizes weights to FP16 before the matmul (vLLM source), and that overhead sits on the critical path (the bandwidth savings will show up in prefill sized batches) and therefore the stack is the clearest example in this post of an optimization that improves every aggregate metric while making the per user experience terribly worse.
Hence, if your workload has prefix sharing, things like RAG, system prompts, document QA, code review over a known codebase - turn on prefix caching. Free lunch (even the docs call it that). The next best option depends on your dominant profile would be admission control for long output traffic, separate clusters for short output traffic, because no vLLM flag fixes the waiting-in-line problem for SISO at 32 RPS.
Essentially, everything else in the matrix earns its place by losing. The diagnosis of the entire thing was the fun part.
So what
Inference optimization is a diagnosis problem, much like a Sherlock Holmes' story line, except you just play with flags and kernels.
Every now and then someone comes up with a new optimization, and shows the exact benchmark where it outperforms others. But what happens when others are stacked together? What happens when my workload is totally different from theirs? Why should I care for long conversations when my entire work is to handle 10 words at a time?
We also saw that AWQ and the stacked config are examples of the same failure mode because the aggregate metrics improve while per user experience degraded badly. Despite the throughput going up, the goodput goes to zero.
The matrix is actully the whole post in one table. No column is uniformly green. No row is served well by everything. The right configuration is the one that matches the traffic shape, and most deployments don't know their traffic shape because they never measured it (or do they?)
I think that's the actual job - not picking the optimization but figuring out what's slow and why, before reaching for the toolbox.
Code is at datavorous/to-fa. If this is the kind of systems work you need done -
get in touch (I am looking for an internship)
References
Gil Tene - how not to measure latency
BentoML - LLM inference metrics / goodput
Acknowledgements
I built my own benchmarking harness for this, which was fine, but I later found out GuideLLM (RedHat) already does most of what I wrote. Legare Kerrison's Devoxx UK talk covers it well - would have saved me a weekend. Thanks for putting that out.

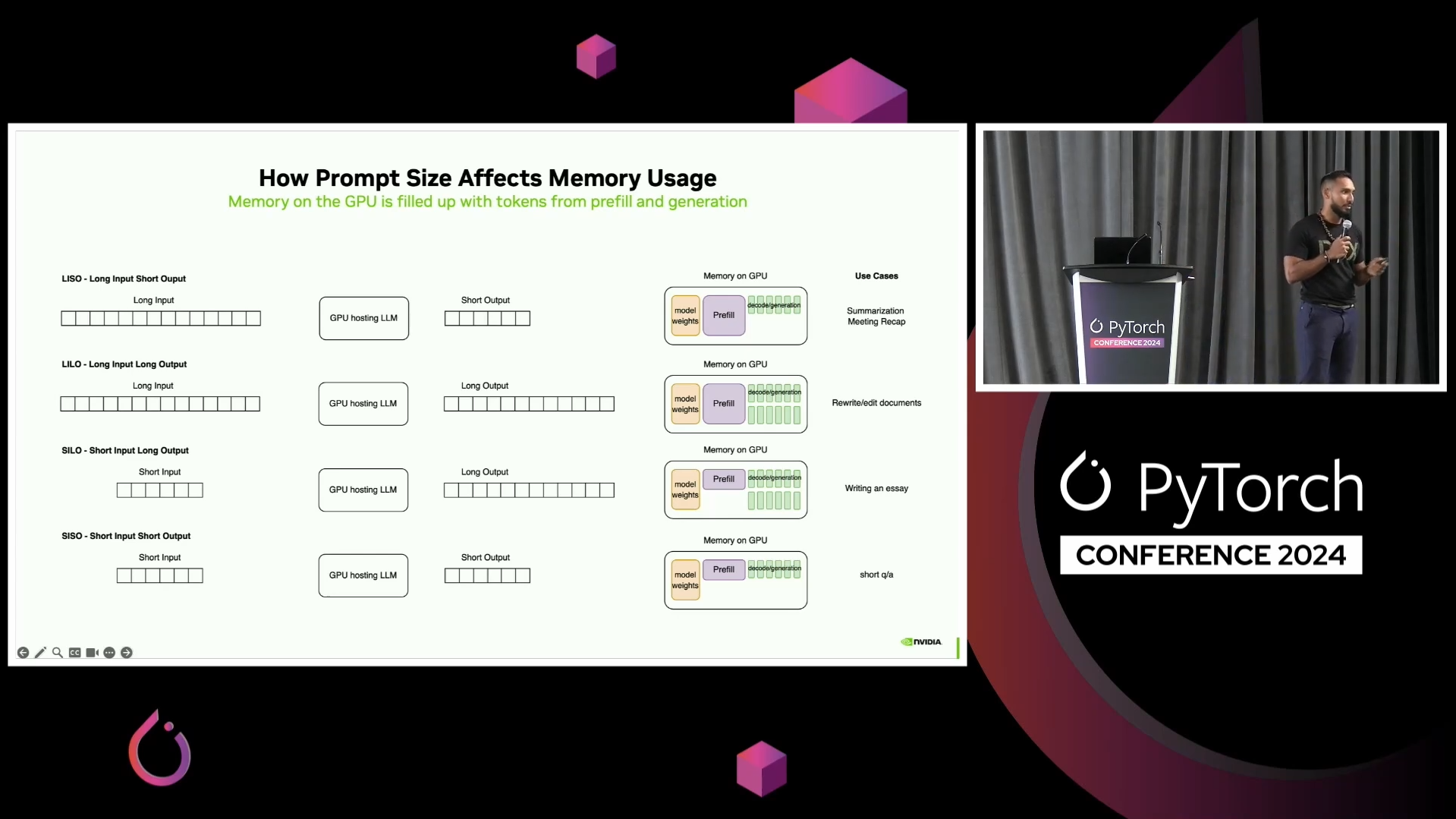
The SISO/SILO/LISO/LILO framing came from Mark Moyou's PyTorch talk (Nvidia). Before watching it I hadn't thought to treat traffic shapes as distinct objects with different hardware bottlenecks. That framing is the whole premise of this post.